somehow, the system finds
its own mistakes.
Every recommendation logged. Every outcome checked. Every error corrected before it happens again.

Predict. Activate. Observe. Adjust.
This is the Karpathy loop — the pattern behind every AI system that gets better with use. For someboty, it runs three times a week.
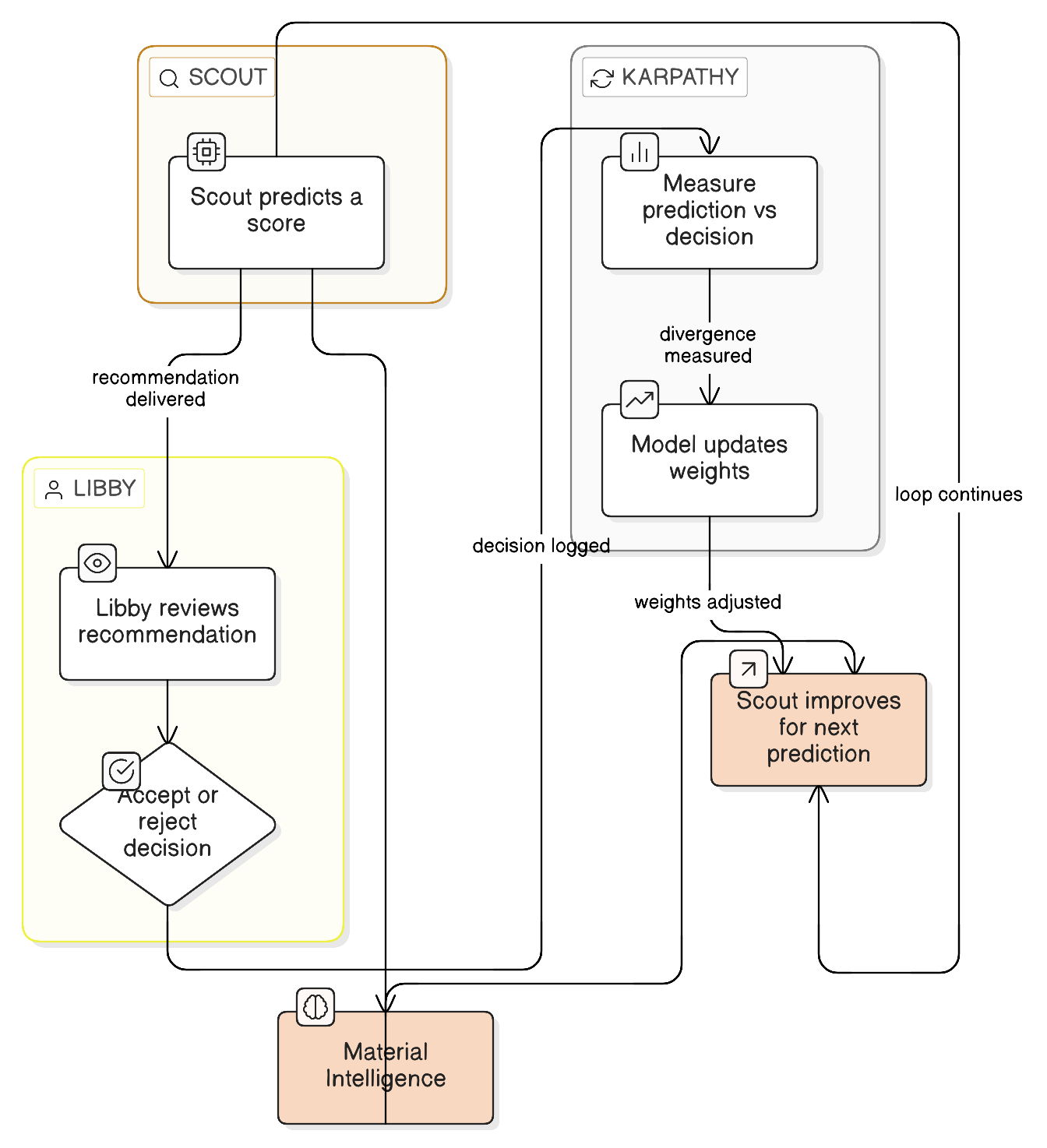
the karpathy loop · predict → activate → observe → adjust · someboty · 2026
After a month: Scout isn't guessing. It's calibrated to your portfolio. After a year: it knows which creator types convert for which brands.
We call it somefink — the self-learning calibration engine that turns every activation into a better prediction.
148 predictions. The learning has started.
The system has made 148 predictions about which creators fit which brands. It has already caught its own blind spots — a geography gate automatically rejected 100 creators who weren't UK-based before anyone needed to look. 48 qualified UK creators are loaded, scored, and waiting for their first activation.
The outcome data — which creators actually drove GMV, which ones returned product, which ones never posted — already lives inside TikTok Seller Center. The moment an agency connects that data, somefink starts learning from real results. Not after five weeks. From day one.
One scoring engine. Two applications.
Joe Yates is building LiveHost — the operating system for live host scheduling and management. A marketplace where live commerce hosts and brands find each other.
The matching problem LiveHost solves — does this host fit this brand? — is structurally identical to the matching problem Scout already solves. Same scoring dimensions. Same calibration loop. Same feedback mechanism.
One infrastructure. Two applications. The intelligence transfers.
The infrastructure is live. somefink is running.
Every creator Somerce activates is a new data point.
Every data point makes the next recommendation more accurate.